SEC504: Hacker Tools, Techniques, and Incident Handling
SEC504Offensive Operations
Like a tech writer in the 90s, I set out to review tools for indexing and searching file names as well as common patterns of data in SMB shares.

Open SMB shares are a boon for a pen tester, and a security disaster for most organizations. People copy files to a community share, leave the organization, or forget what they copied. Other people are afraid to delete stale content, because no one knows if it's important. The data grows over time, and is a valuable source of sensitive information disclosure for attackers.
As a pen tester, if I find an SMB share I can quickly look for file names with sensitive data using PowerShell and Get-ChildItem -Recurse -Path . or a CMD prompt with dir /r /s /b. A search for *password*, *key*, *secret*, *confidential*, etc., is often fruitful. But it's only surface-level analysis. What about invoices with sensitive customer information scanned in as 0384713298.pdf? What about a SQL-based database export named stuff.txt.gz? What about an EPHI app page accidentally saved as a file called View - 2022-05-22_files?
What pen testers need is a tool that can index SMB shares and search not just file names, but also for common patterns of data that would indicate sensitive information disclosure.
This is what I set out to find. I want a tool that will:
I asked around and none of my pen tester friends had any great solutions. Like a PC Magazine tech writer in the 90s, I set out to review tools until I found what I was looking for.
Spoiler alert: No tool is perfect, but you might find something that meets your specific needs. Read on for details, or skip to the conclusion below.
https://copernic.com/en/desktop/
Copernic Desktop Search is a commercial desktop search solution, intended for people who need to search through their files on their local system. It also supports searching network mapped drive letters so you can use it for SMB server searches too. It appears to be designed to the non-technical audience, and lacks any advanced search capabilities.
Copernic claims that it's product supports searches "over 150 file types" (ref), but doesn't include support for lots of common ASCII-based files including .json, .sql, and others. You can manually add them, but one would think Copernic would have a better list to match this claim.
Copernic's main benefit is performance -- after indexing completes, you can search through a lot of data very quickly. However, it has some subtle bugs, including the inability to identify partial string matches in the middle of a string if the string includes an underscore (it returns hits for aws_access_key, but not for access_key for example; I have an open ticket with Copernic support to address this bug).
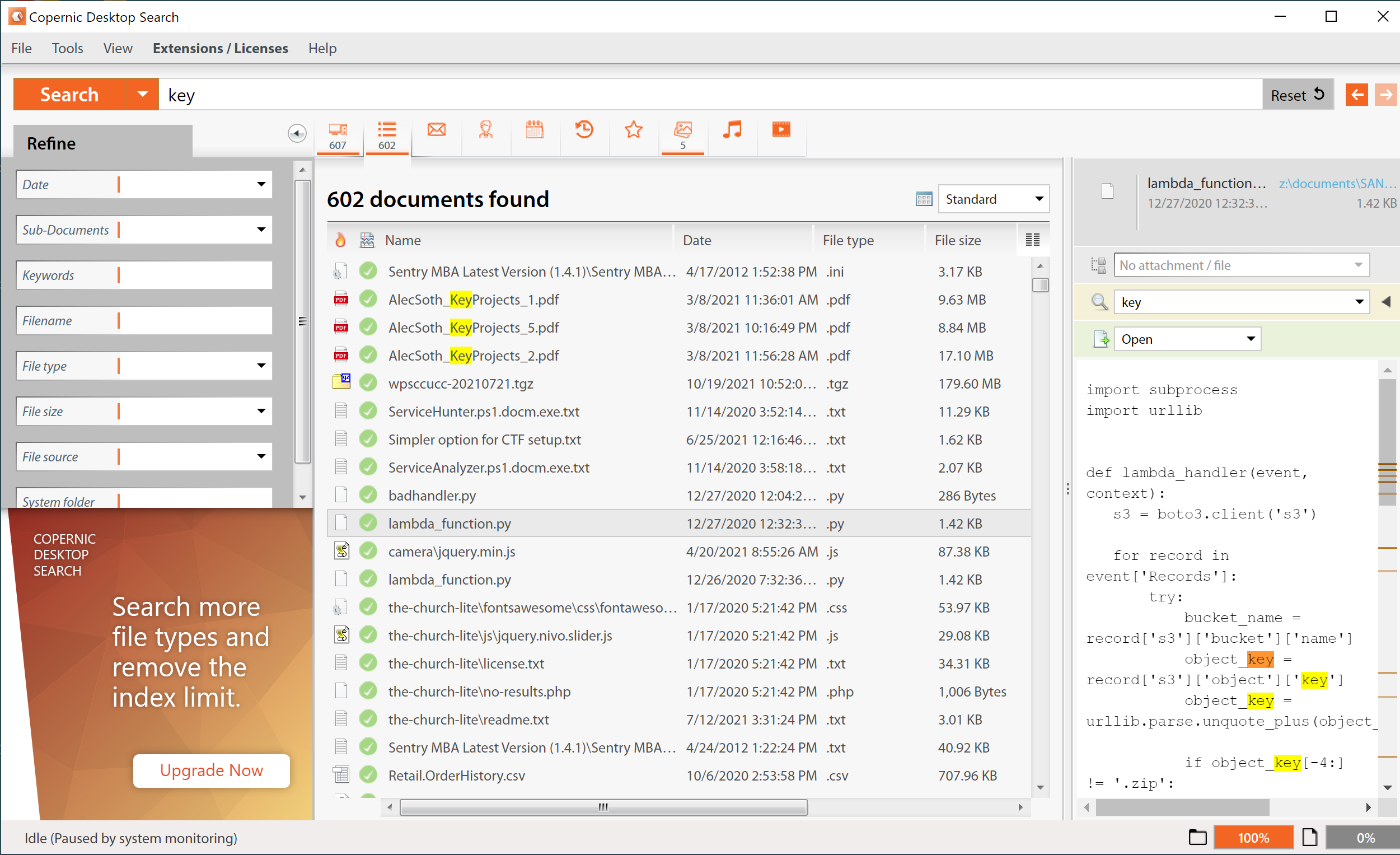
Useful for people who need to find common office files for exact keyword matches. The only solution that had really solid OCR scanning for image files. Not great for hunting unknown sensitive data in SMB shares.
Everything by Voidtools is a free, beautifully-minimal search tool for file names on the local file system, but not much else. Maybe it doesn't belong in this comparison, since it's only content search functionality is on-demand (e.g., it does not build a file content index, it searches file content on-demand in an advanced search, which will be slow compared to other tools that calculate the content index in advance), but it is popular with users, so I reviewed it as a potential solution.
One main drawback for Everything is that is needs to run as an administrator to index NTFS volumes, due to how Microsoft controls NTFS indexing. For SMB share searching this isn't a problem, though other use cases may require you to run Everything as an administrator or install a companion service with administrator privileges.
Everything relies on local programs installed to provide content indexing (for example, you need Adobe Acrobat installed on the Everything search system to search inside PDF files) instead of supplying its own file content parsers. Same for Microsoft Office documents, which limits the search results for content searches (annoyingly, if you don't have these tools installed, Everything just ignores the file content).
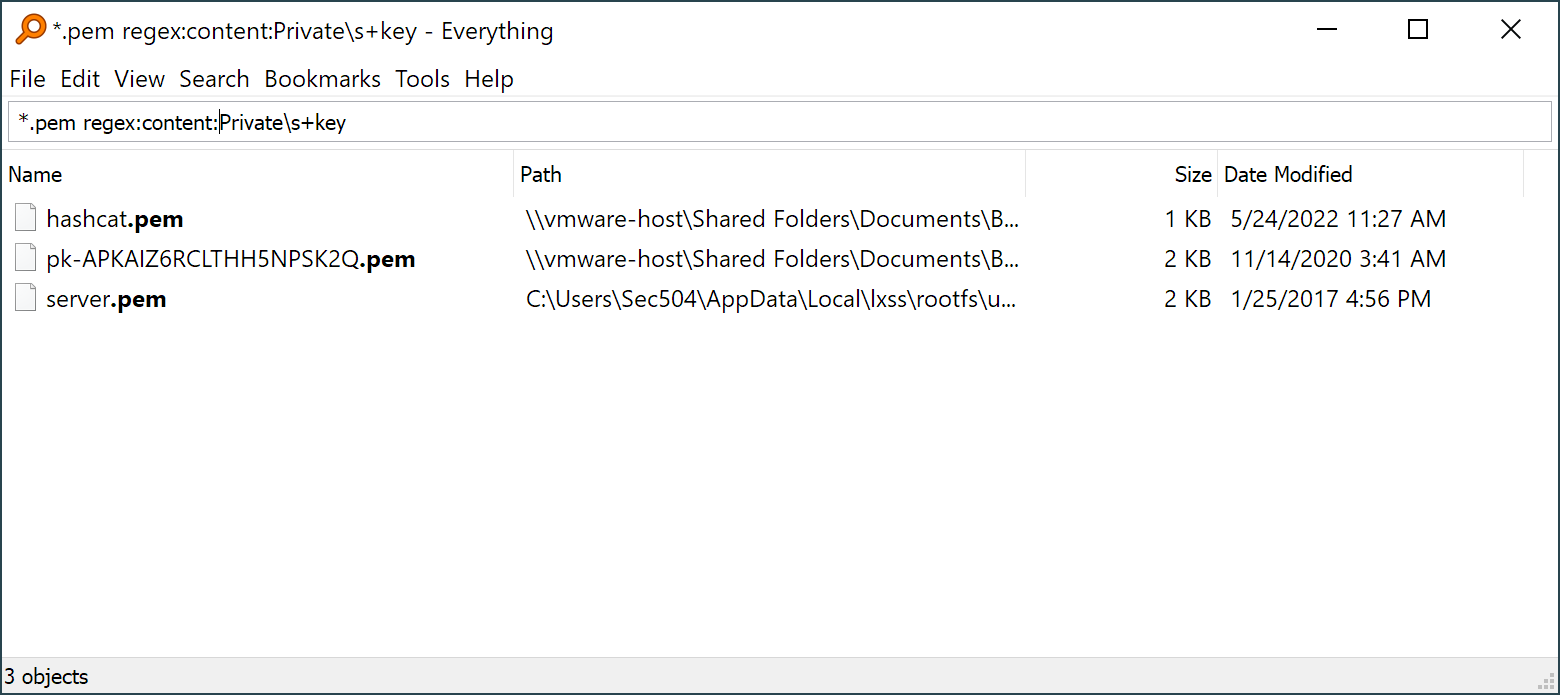
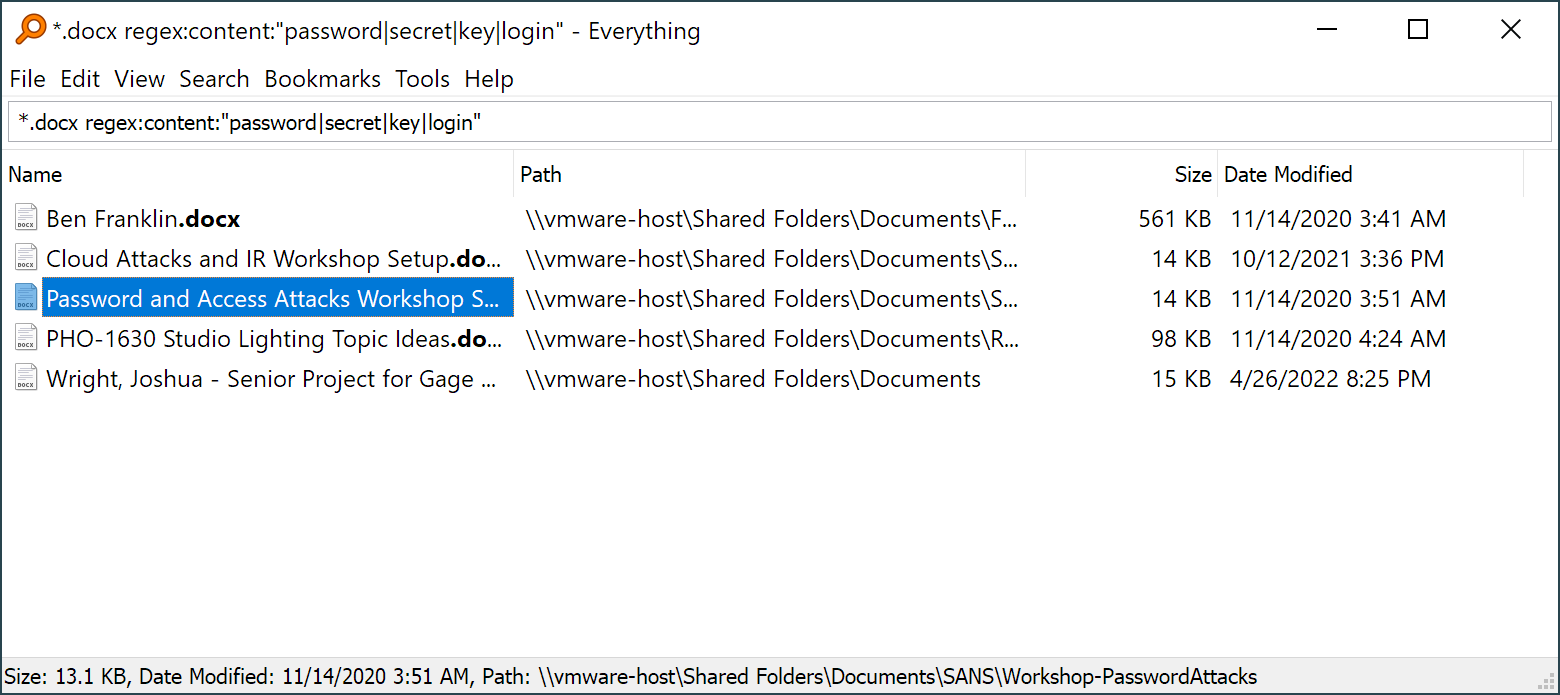
Everything is great for searching files by name, but less-than-ideal for discovering sensitive data by content. It's really easy to build a search that looks like it is valid and returns no or few matches, but is really an unreported error in your search syntax. Keep a local repo of target files to validate your searches against if you plan to use this tool in an engagement against unknown target data.
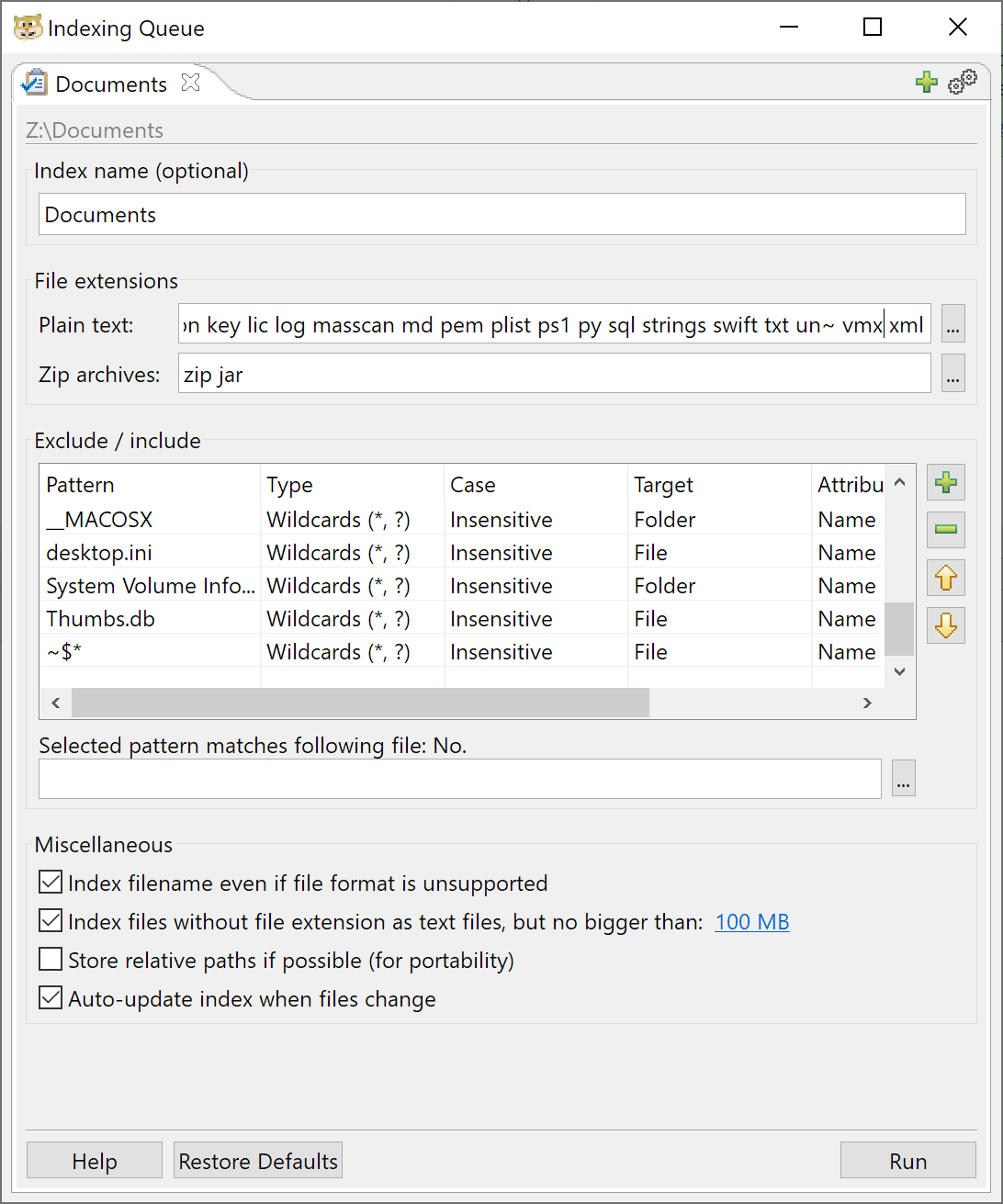
DocFetcher Pro is a low-cost ($40), Java-based file search utility using an Apache Lucene back end to store and process data. Like Copernic Desktop Search, it indexes file names and content. It has regular expression support as part of the Lucene search syntax, which got my hopes up pretty high.
DocFetcher Pro allows you to specify the file name extensions that it should treat as text files, defaulting to some common source code files. If you add common data filename extensions (JSON, CSV, XML, etc.) you'll be able to index and search these files as well. It seems like DocFetcher Pro could use file magic to identify these files automatically, but it doesn't. (Oh, you didn't SPECIFY that you wanted to index .SQL files, I'm just going to ignore those.)
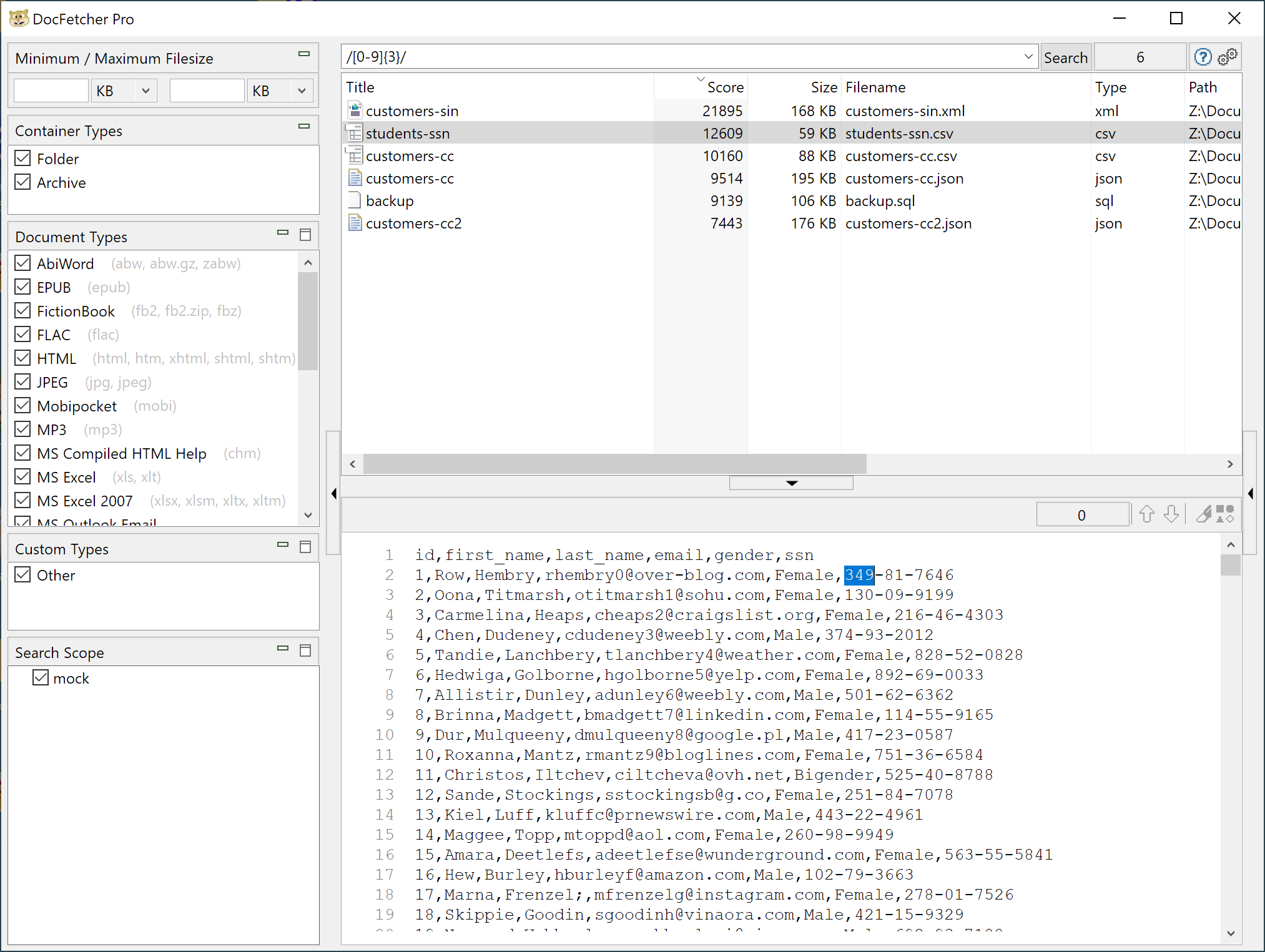
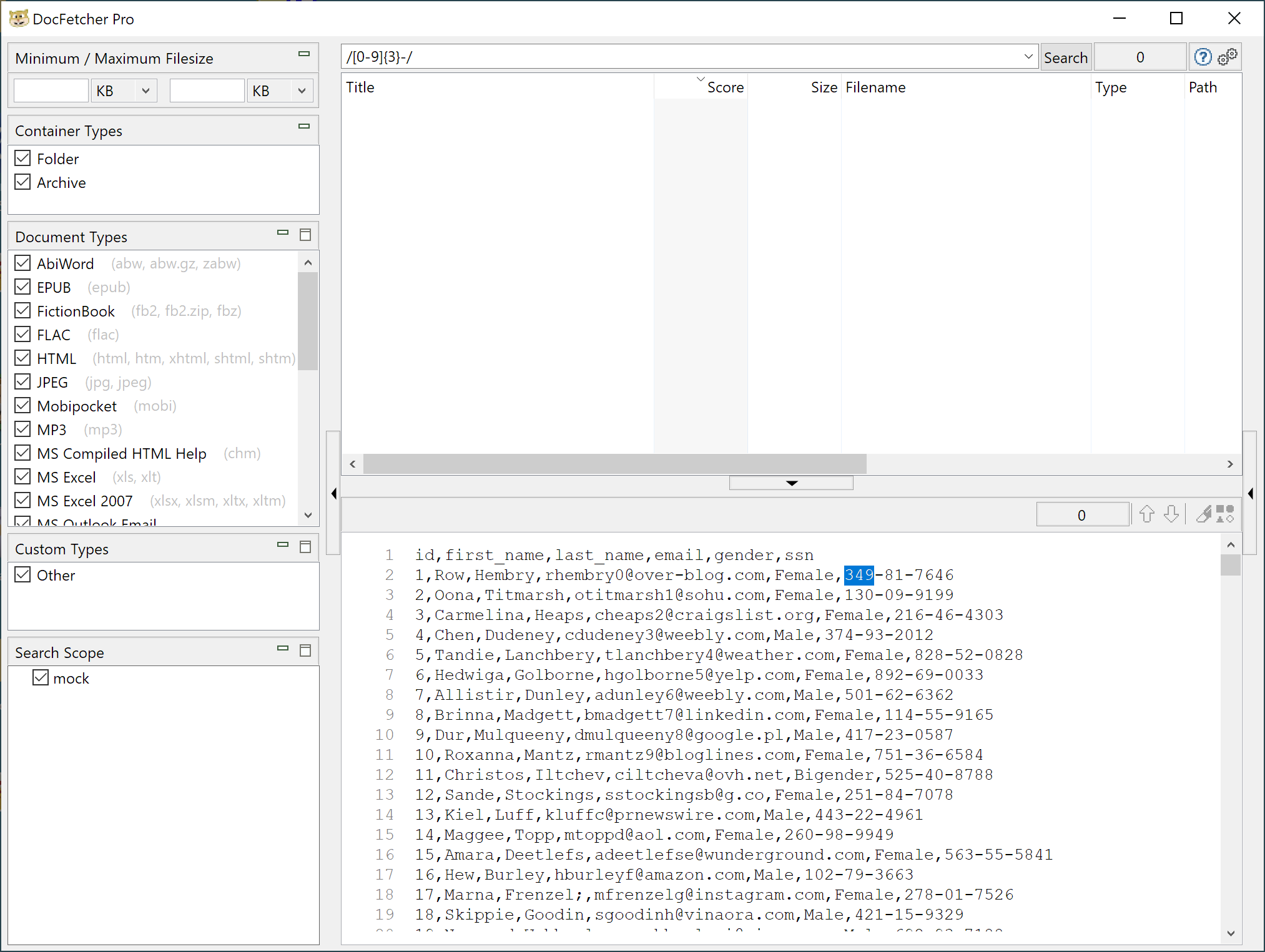
Relying on the Lucene backend for search, DocFetcher Pro takes advantage of a lot of flexibility for searching, with built-in support for decoding lots of popular file types and archive formats. Lucene supports regular expressions for searching data (which includes file names and extracted strings from DocFetcher Pro) but is sadly broken for use in regular expression matching with DocFetcher Pro. DocFetcher Pro relies on Lucene's StandardTokenizer feature to split free-form text into content to be indexed, which will split words on common separators (space, period, hyphen, etc.) This behavior allows DocFetcher to search for numeric patterns such as three consecutive digits using a regular expression, but not to search for three consecutive digits, followed by a hyphen, followed by more digits (e.g., [0-9]{3} works OK, but [0-9]{3}- fails to match anything in the index).
When I brought this issue up with the developer he was responsive and encouraging, but essentially pointed to "this is how Lucene works" as a fundamental limitation. The inability to search content for numeric patterns like Social Security Numbers (SSNs) and Social Identification Numbers (SINs) significantly limits DocFetcher Pro's usefulness.
DocFetcher lacks the professional qualities of Copernic Desktop Search, and the minimalism of Everything. If you don't need search capabilities that cover multiple combined search terms it may be useful, but lacks the ability to do matching across whitespace or common punctuation separators.
https://www.mythicsoft.com/filelocatorpro/download/
FileLocater Pro (or Agent Ransack, duplicate tools with different names for $REASONS that make product managers cringe) is commercial software with a free reduced-functionality version. Like Everything, it doesn't create a content index, making it very slow to search through a large set of files. The interface of FileLocater Pro is a little more intuitive than Everything, and while it has a portable version that doesn't require an installer, it brings over a thousand files to the party (compared to the party of 1 for Everything).
After a few seconds with the interface I kicked off a search for a regular expression pattern that matches US social security numbers. FileLocater Pro searched all files for the content, matching some PhotoShop files in my target data set, but also some CSV and SQL files I had stashed away. The problem is the search time; it took over 20 minutes to complete one search, since there is no content indexing.
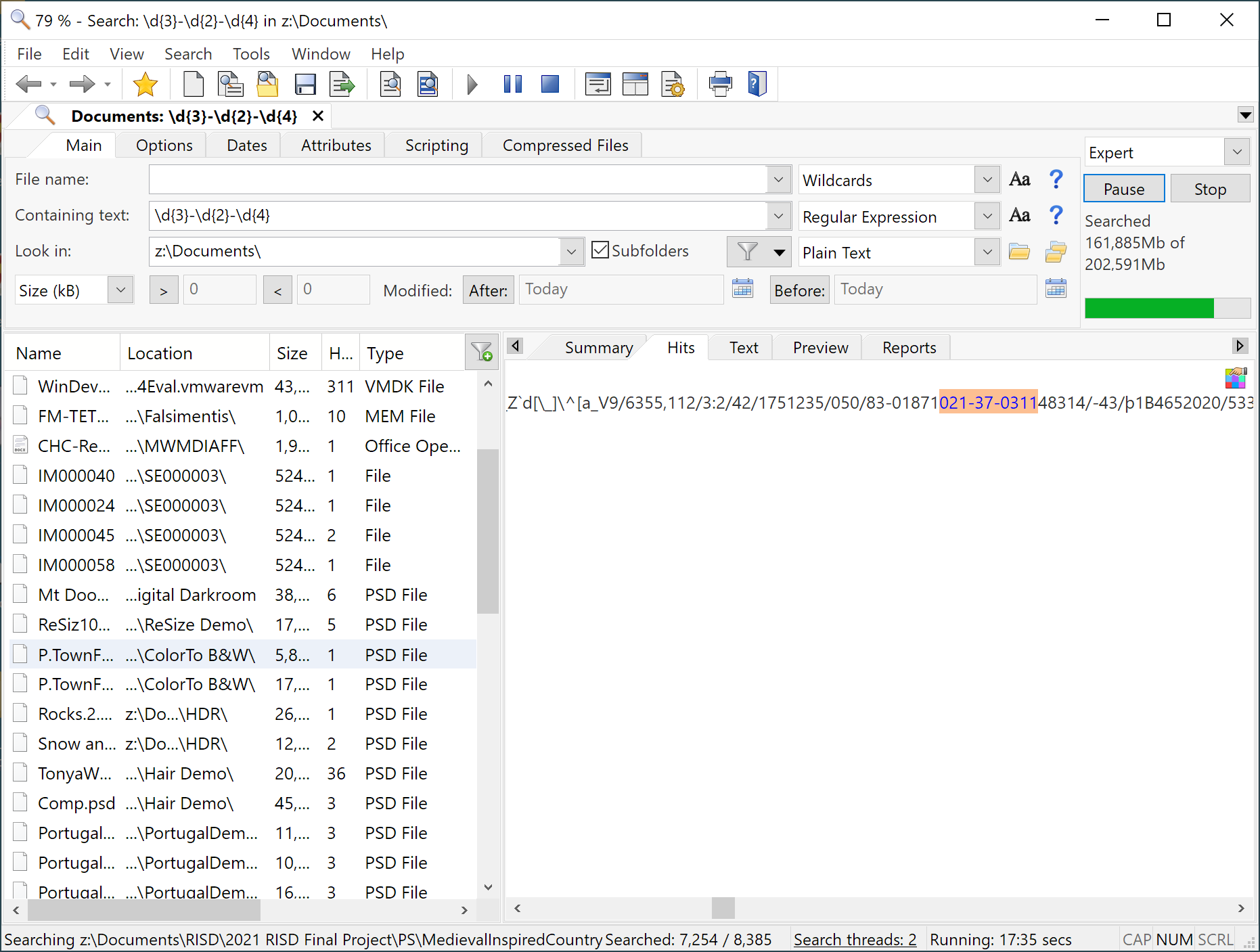
I can imagine a single, complex search to find all of the potential hits for sensitive data on a SMB share and letting it run for however long it would otherwise take to create an data content index, but I think that's probably unreasonable for most use cases. That's too bad, because otherwise FileLocater Pro has a lot going for it.
https://www.lesbonscomptes.com/recoll/index.html
Recoll is open-source software written in Python that leverages the functionality of several other tools to build a name and content index for supported data types. A Windows version is available for a small contribution.
Recoll does not support regular expression searches, but the documentation indicates it supports several wildcard pattern matching features. I searched my indexed data for the Canadian SIN using the pattern [0-9][0-9][0-9]-[0-9][0-9][0-9]-[0-9][0-9][0-9] but it failed to match the target data. Opening a ticket for assistance the author reached out explained that what I wanted to do would not work due to some undocumented tool limitations. They were very nice about it, though.
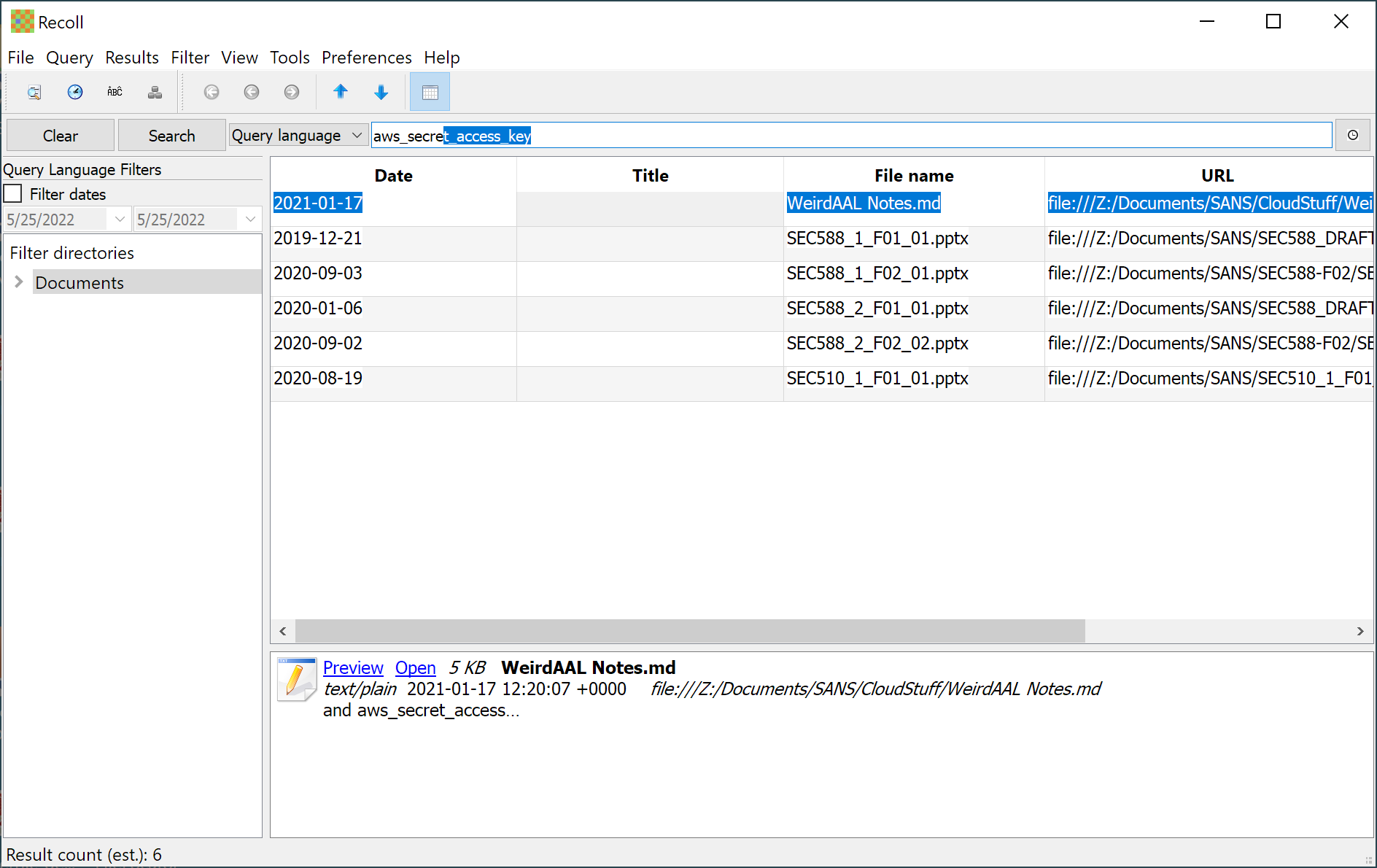
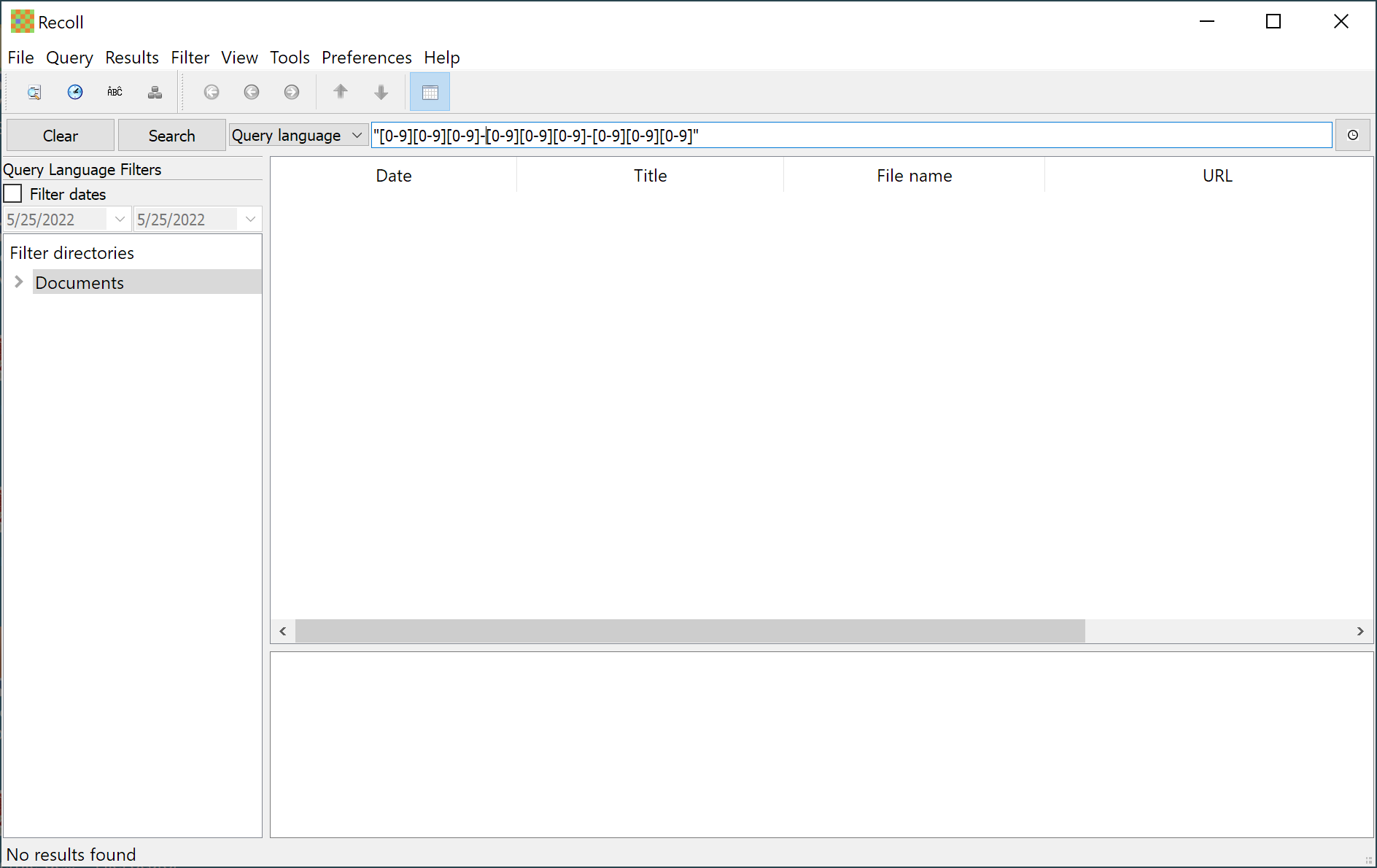
Recoll is free and open-source, with a small, one-time cost for a Windows port. It indexes file names and content with lots of supported file types for quick data searching. Use it for searching for simple strings, but don't ask it to do complex pattern matching.
https://www.jam-software.com/ultrasearch_professional
UltraSearch Professional is $399 for a professional consultant license ($55.95 for a professional single license). It does not index files, instead using the NTFS Master File Table (MFT) to perform quick file name matching.
UltraSearch Professional supports content searching, but does not build an index, making it slow to look for terms. The documentation indicates that is supports regular expressions, though this may be for file names and not content since there is also an UpVoty request for regex content searches. UltraSearch Professional has support for a Query Composer interface to help learn the UltraSearch Professional syntax for searching, but otherwise doesn't offer a lot of benefits over the free Everything tool that also does not build a content index.
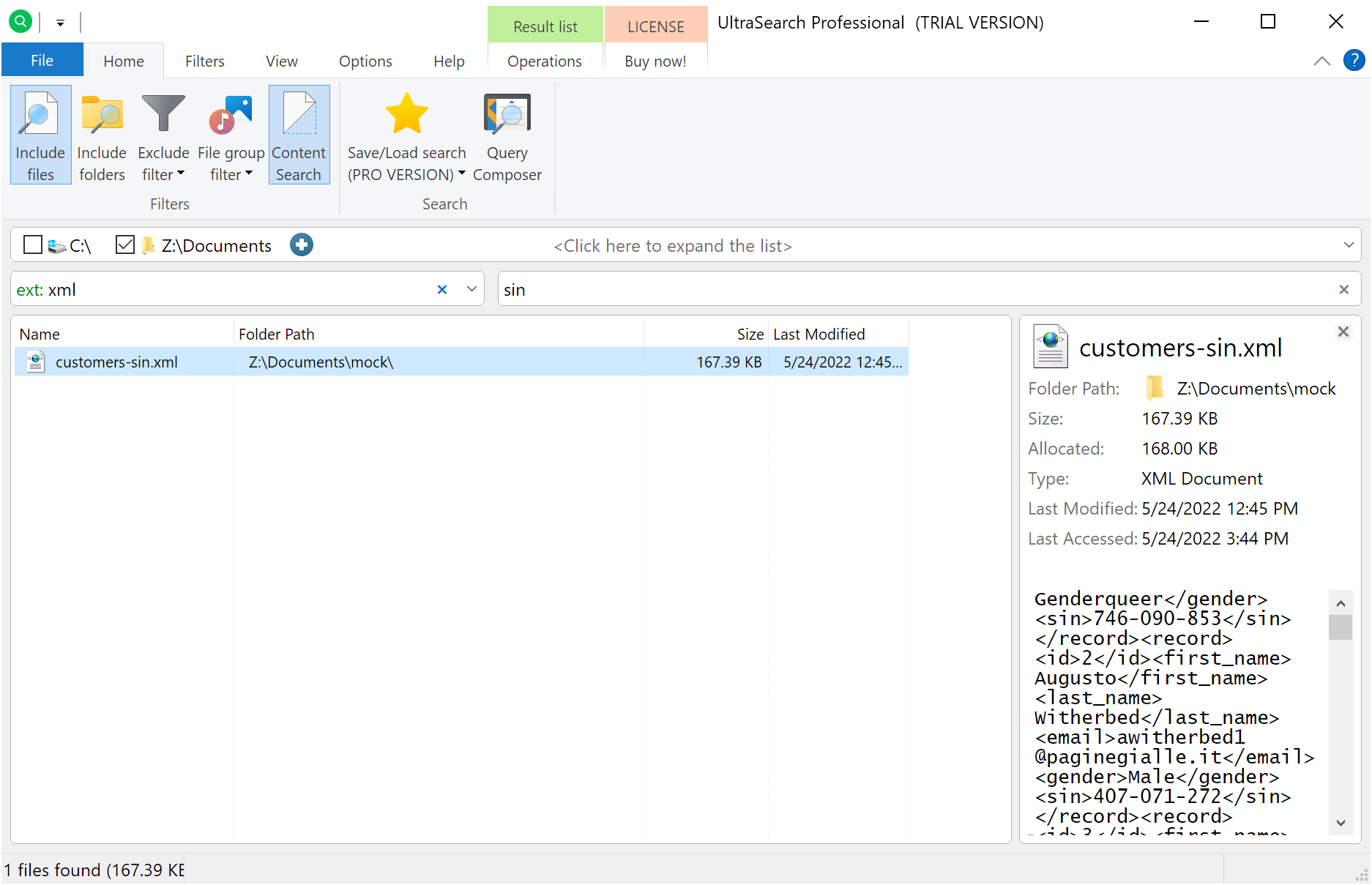
UltraSearch Professional looks like typical Windows software with an intuitive ribbon interface and handy learning tools such as the Query Composer. While it supports simple string and regular expression searches for content, it does not index content in advance which makes these searchers painfully slow. UltraSearch Professional has similar features to Everything, but at $399 for a professional consultant license vs. Everything for free.
Searchmonkey is a GPL tool written in Java. Running it on Windows showed a font size that's definitely going to fail WCAG compliance.
PowerGrep is a commercial tool for Windows to offer grep-like functionality, but also has support for modifying files as well (sort of like sed and grep functionality, with a retro GUI, for $159). It supports regular expressions, but doesn't index data, making searches slow.
Changing content in files using pattern matching is a valuable feature, but outside of the scope of this review. PowerGrep offered similar functionality to the free Everything tool in this regard, but includes its own file parsing support to search inside PDF and common office document types.
PowerGrep might be a better contender than Everything to search file content on demand, but lacking an index, OCR capabilities, and other features it didn't bubble up as something that could meet my needs.
The amazing toolset PowerSploit by Will Schroeder (@harmj0y) includes several utilities to discover and scan SMB shares. The Find-InterestingFile module looks for files by name that match the following patterns:
This is super handy for quick searching, but doesn't look into the content of files. Useful, but only a partial solution for identifying sensitive SMB share information.
I used 🤏 to indicate almost-but-not-quite in the table below.
| Tool | Cost | Multi-platform | Content Indexing | Content Pattern Matching | OCR | Portable |
|---|---|---|---|---|---|---|
| Copernic Desktop Search | $55/year | ✅ | ✅ | |||
| Everything | $0 | ✅ | ✅ | |||
| DocFetcher Pro | $40 | ✅ | ✅ | 🤏 | ✅ | |
| FileLocater Pro | $124 | ✅ | ||||
| Recoll | €5 - €20 | ✅ | ✅ | 🤏 | ||
| UltraSearch Professional | $399 | ✅ | ✅ |
Sadly, nothing I could find really met my goals. Copernic Desktop Search is useful if you are only interested in finding static search terms, or if OCR scanning of image files is a high priority. DocFetcher Pro seemed like a good alternative, but limitations between the app and the backend data storage prevents really useful searches for data pattern matching. Everything is convenient as a tool that imposes a minimal footprint on the target system and could be configured to make one complicated regular expression search for every possible keyword, but the lack of indexing support makes more than one search a painfully slow proposition.
In the meantime, I'm still on the hunt for a solution. If you have any ideas, reach out to me on Twitter @joswr1ght or email josh@willhackforsushi.com. If I can find the perfect solution (or if I just throw my hands up and write my own solution), I'll share the details in my Twitter feed.
